Audio Pipeline
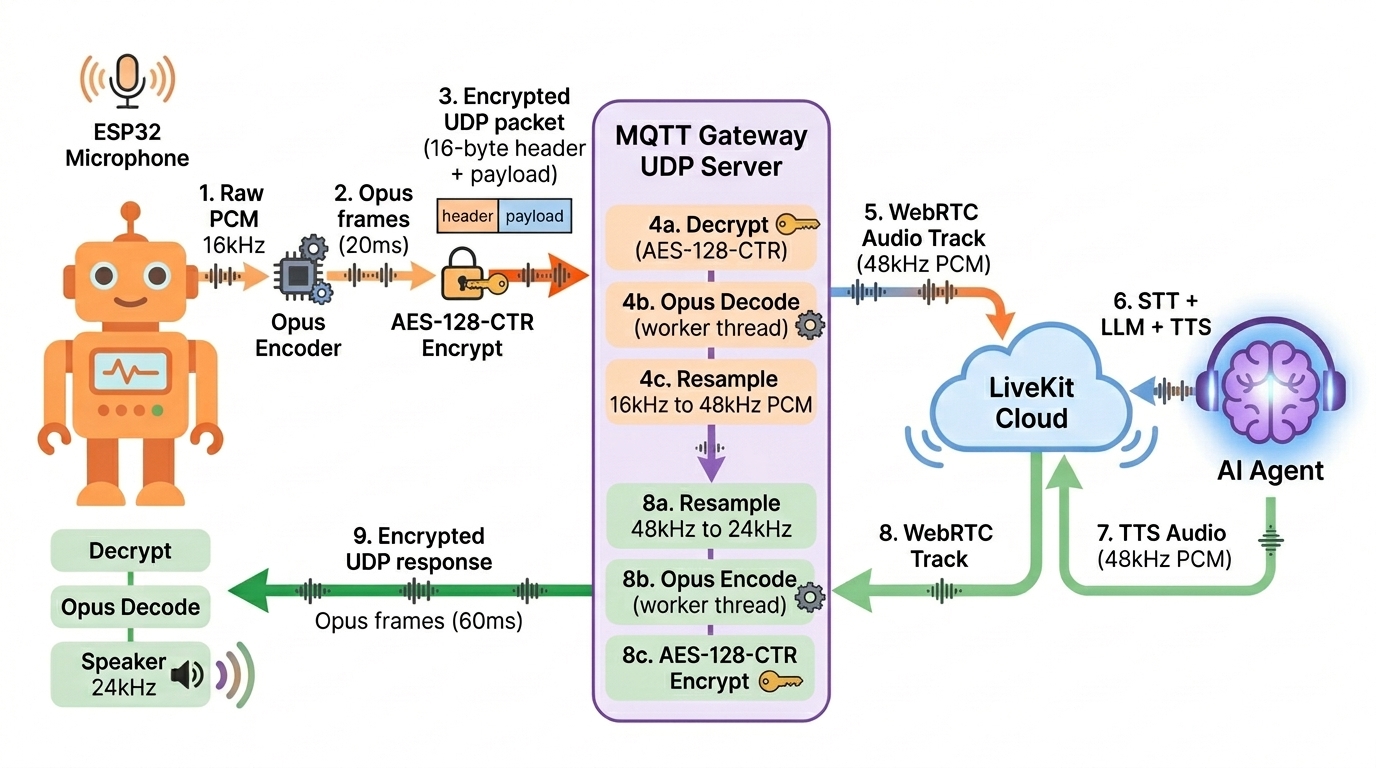
The gateway handles two parallel audio flows: uplink (device microphone → LiveKit) and downlink (LiveKit agent voice → device speaker). All audio is Opus-encoded and transmitted over UDP with AES-128-CTR encryption.
UDP Server Setup
The UDP socket is created in MQTTGateway.start() using Node.js dgram:
this.udpServer = dgram.createSocket('udp4');
this.udpServer.bind(this.udpPort); // default port: 1883 (UDP_PORT env var)
The gateway binds on all interfaces (0.0.0.0). The public IP returned to devices in the hello response comes from PUBLIC_IP env var (default 127.0.0.1).
The UdpServer class in gateway/udp-server.js wraps the same dgram socket pattern with a handler registration API.
Packet Structure
Every UDP packet has a 16-byte fixed header followed by encrypted audio payload:
| Offset | Size | Field | Description |
|---|---|---|---|
| 0 | 1 byte | type | Always 0x01 for audio packets |
| 1 | 1 byte | reserved | Always 0x00 |
| 2 | 2 bytes | payloadLength | Big-endian uint16, length of encrypted payload |
| 4 | 4 bytes | connectionId | Big-endian uint32, identifies the VirtualMQTTConnection |
| 8 | 4 bytes | timestamp | Big-endian uint32, audio timestamp in ms |
| 12 | 4 bytes | sequence | Big-endian uint32, monotonically increasing |
| 16 | N bytes | payload | AES-128-CTR encrypted Opus audio data |
Packets shorter than 16 bytes are silently discarded. The gateway uses connectionId at offset 4 to look up the connection:
const connectionId = message.readUInt32BE(4);
const connection = this.connections.get(connectionId);
AES-128-CTR Encryption
Each device session gets a unique 16-byte key and nonce generated at hello time:
this.udp.key = crypto.randomBytes(16); // 16-byte AES key
this.udp.nonce = this.generateUdpHeader(0, 0, 0); // 16-byte nonce (same format as packet header)
this.udp.encryption = 'aes-128-ctr';
The key and nonce are sent to the device in the hello response as hex strings:
"udp": {
"encryption": "aes-128-ctr",
"key": "0102030405060708090a0b0c0d0e0f10", // 32-char hex
"nonce": "0102030405060708090a0b0c0d0e0f10" // 32-char hex
}
For outgoing (gateway → device) packets, VirtualMQTTConnection.sendUdpMessage uses streamingCrypto.encrypt from core/streaming-crypto.js:
const encryptedPayload = streamingCrypto.encrypt(
payload,
this.udp.encryption, // 'aes-128-ctr'
this.udp.key,
header // 16-byte header used as IV
);
const message = Buffer.concat([header, encryptedPayload]);
The 16-byte packet header is used as the AES-CTR IV, meaning each packet has a unique IV derived from its timestamp and sequence number.
For incoming (device → gateway) packets, streamingCrypto decrypts using the same key/nonce in onUdpMessage.
Uplink Path: Device → LiveKit
ESP32 microphone
│ Opus encoded at 16 kHz mono, 60 ms frames
│ AES-128-CTR encrypted
▼
UDP socket (port 1883)
│
MQTTGateway.onUdpMessage
│ Parse 16-byte header, look up VirtualMQTTConnection by connectionId
│
VirtualMQTTConnection.onUdpMessage
│ Decrypt payload (AES-128-CTR)
│ Forward to bridge.onUdpMessage
│
LiveKitBridge
│ Decode Opus → PCM via WorkerPoolManager.decodeOpus
│ Decoder config: 16000 Hz, 1 channel (mono)
│ Frame size: 960 samples (60 ms at 16 kHz)
│
LiveKit room local participant
└── Publish PCM audio track → LiveKit Cloud → AI agent
Sample rate: 16 000 Hz (incoming from device) Channels: 1 (mono) Frame duration: 60 ms Frame size: 960 samples = 1 920 bytes of 16-bit PCM
Downlink Path: LiveKit → Device
AI agent (livekit-server)
│ Produces Opus audio track in LiveKit room
│
LiveKitBridge
│ Subscribes to agent audio track
│ Receives Opus frames from LiveKit
│
├── Audio format detection (audio-processor.js)
│ detectAudioFormat: Shannon entropy >= 6.0 → Opus, < 6.0 → PCM
│ checkSilence: discard fully silent frames (all zeros, maxAmplitude < 10)
│
WorkerPoolManager.encodeOpus (if input is PCM)
│ Encode PCM → Opus via @discordjs/opus
│ Encoder config: 24000 Hz, 1 channel (mono)
│ Frame size: 1440 samples (60 ms at 24 kHz)
│ Frame bytes: 2880 bytes of 16-bit PCM input
│
VirtualMQTTConnection.sendUdpMessage
│ Generate 16-byte header (type=1, payloadLength, connectionId, timestamp, sequence)
│ AES-128-CTR encrypt Opus data using header as IV
│ Concat: [16-byte header] + [encrypted Opus]
│
UDP socket
└── Send to device.udp.remoteAddress (address + port learned from first inbound packet)
Sample rate: 24 000 Hz (outgoing to device) Channels: 1 (mono) Frame duration: 60 ms Frame size: 1 440 samples = 2 880 bytes of 16-bit PCM
Audio Constants
From constants/audio.js:
| Constant | Value | Description |
|---|---|---|
INCOMING_SAMPLE_RATE | 16 000 Hz | Device microphone → LiveKit |
OUTGOING_SAMPLE_RATE | 24 000 Hz | LiveKit → device speaker |
CHANNELS | 1 | Mono throughout |
INCOMING_FRAME_DURATION_MS | 60 ms | Uplink frame duration |
OUTGOING_FRAME_DURATION_MS | 60 ms | Downlink frame duration |
INCOMING_FRAME_SIZE_SAMPLES | 960 samples | 16 000 × 0.060 |
OUTGOING_FRAME_SIZE_SAMPLES | 1 440 samples | 24 000 × 0.060 |
INCOMING_FRAME_SIZE_BYTES | 1 920 bytes | 960 × 2 (16-bit PCM) |
OUTGOING_FRAME_SIZE_BYTES | 2 880 bytes | 1 440 × 2 (16-bit PCM) |
Opus Codec Details
The gateway uses @discordjs/opus (native Node.js addon) via the OpusEncoder class, which handles both encoding and decoding.
Codec instances are initialized in core/opus-initializer.js:
opusEncoder = new OpusEncoder(OUTGOING_SAMPLE_RATE, CHANNELS); // 24000 Hz, mono
opusDecoder = new OpusEncoder(INCOMING_SAMPLE_RATE, CHANNELS); // 16000 Hz, mono
The OpusEncoder.decode method is used for decoding despite the class name — this is by design in the @discordjs/opus API.
Audio Worker Thread Architecture
CPU-intensive Opus encode/decode operations run in a pool of worker threads to prevent blocking the main event loop. This is implemented in core/worker-pool-manager.js using audio-worker.js.
Pool Configuration
| Parameter | Value | Description |
|---|---|---|
| Minimum workers | 4 | Always maintained |
| Maximum workers | 8 | Cap based on CPU cores |
| Scale-up threshold | 70% load | Workers are >= 70% busy |
| Scale-down threshold | 30% load | Workers are <= 30% busy |
| Scale-up CPU threshold | 60% | CPU usage triggers scale-up |
| Scale check interval | 10 s | How often to evaluate load |
| Scale-up cooldown | 30 s | Minimum time between scale-up events |
| Scale-down cooldown | 60 s | Minimum time between scale-down events |
Worker Selection
The pool uses least-loaded selection (not round-robin) to minimize latency jitter: the worker with the fewest pending requests is chosen for each encode/decode operation.
Message Protocol (main thread ↔ worker)
Workers communicate via postMessage/on('message'). ArrayBuffers are transferred (zero-copy) for audio data.
Message type | Direction | Description |
|---|---|---|
init_encoder | → worker | Set encoder config { sampleRate: 24000, channels: 1 } |
init_decoder | → worker | Set decoder config { sampleRate: 16000, channels: 1 } |
encode | → worker | PCM → Opus. Params: { sessionId, buffer, byteOffset, byteLength, frameSize } |
decode | → worker | Opus → PCM. Params: { sessionId, buffer, byteOffset, byteLength } |
cleanup_session | → worker | Free per-session codec state { sessionId } |
| result | ← worker | { id, success: true, result: { data, processingTime, inputSize, outputSize } } |
| error | ← worker | { id, success: false, error: "...", stack: "..." } |
Per-Session Codec Instances
Each worker maintains a sessions Map of sessionId → { outgoingEncoder, incomingDecoder }. Encoder and decoder instances are created lazily on first use and destroyed when cleanup_session is received. This avoids shared-state issues when multiple devices are connected simultaneously.
Timeouts
| Operation | Timeout |
|---|---|
init_encoder / init_decoder | 500 ms |
encode / decode | 150 ms |
If a worker does not respond within the timeout, the promise is rejected and the error is counted in the performance monitor.
Audio Format Detection
livekit/audio-processor.js provides utilities used by LiveKitBridge to inspect audio frames before passing them to the encoder:
// Entropy-based format detection
// Opus (compressed) has higher entropy >= 6.0
// PCM (raw waveform) has lower entropy < 6.0
function detectAudioFormat(data) {
const entropy = calculateEntropy(data);
return entropy >= 6.0 ? 'opus' : 'pcm';
}
// Silence detection (16-bit PCM)
// isSilent: all samples are zero
// isNearlySilent: maxAmplitude < 10
function checkSilence(pcmData) { ... }
Silent frames are discarded before encoding to avoid transmitting unnecessary packets.